VirTex: Learning Visual Representations from Textual Annotations
Abstract
1. Introduction
The prevailing paradigm of learning visual representation was pretrining a convolutional network, and it was expensive to scale since it needed pretraining with human annotated images. Therefore, unsupervised pretraining got a lot of attention and achieved some success, but with much bigger datasets. Therefore, researchers try to find more efficient way of supervised pretraining in this paper.
Since image captions provide sementically dense information, lanugauge supervision is appealing. This approach was given as VirTex, using data-efficient way of using natural language as supervision for learning transferable visual representations.
2. Related Work
Weakly Supervised Learning
It finds way to learn from large number of images with nosiy labels, to scale up supervised learning. In this approach, learning is done with large quantities of low quality labels, like automatic labeling or hashtags.
Self-Supervised Learning
It focus on learning visual representations from solving pretext tasks with unlabeled images, such as context prediction, colorization, predicting, clustering, generative modeling, etc. These were based on contrastive learning. They lack semantic understanding, since the methods are based on low-level visual cues.
Vision-and-Language Pretraining
It attempts to learn joint representations of image-text paired data, which can be transferred to multimodal downstream tasks, like visual question answering, visual reasoning, reffering expressions, language-based image retrieval. With the success of BERT, these methods use Transformers. These methods usually requires multi-step pretraining pipelines and pretrained CNN and Transformer.
Concurrent Work
Sariyildiz et al. and Stroud et al. are similar works of learning visual representations.
3. Method
To learn visual representations that can be transferred to downstream tasks, image captioning model of predicting captions from images was trained: a combination of a visual backbone and a textual head. The textual head performs bidrectional captioning. Both components are randomly initialized, then trained to maximize the log-likelihood of the correct caption tokens like:
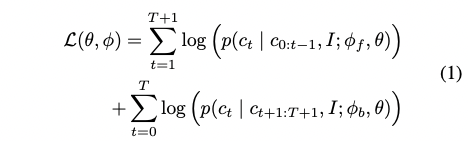
with $\theta, \phi_f, \phi_b$ each refers to parameters of the visual backbone, forward, and backward models repectively. The textual head is discarded when the training is done and the visual backbone is used for transfer to downstream visual recognition tasks.
Language Modeling
Many large scale language models use masked language models (MLMs), but it converged slower than directional models, with poor sample efficiency.
Visual Backbone
It inputs raw image pixels, and outputs a spatial grid of image features, which are used to predict captions. In downstream tasks, linear models attached at the top or just end-to-end backbone are trained for fine-tuning. In pretraining, linear projection layer is applied before passing the visual features to the textual head, to facilitate decoder attention. The layer is removed for fine-tuning.
Textual Head
Using Transformers, the textual head comprises two identical language models. During training, the forward and backward model receives image features from the visual backbone and a caption describing the image. Tokens of C are converted into vectors via learned token and positional embeddings, followed by elementwise sum, layer normalization and dropout. These vectors are processed through Transformer layers. After the masked multiheaded self-attention, those vectors are used for multiheaded attention with image vectors, followed by dropout and residual connection, layer normalization. A linear layer is applied to each vector to predict unnormalized log probabilities over token vocabulary at the top. Both the forward and backward model use same token embedding matrix, which is also reused at the output layers of each model.
Model Size
The width and depth of textual head was varied with hidden size and the number of transformer layers.
Tokenization
The tokninzing used BPE algorithm, which makes fewer lingustic assumptions and exploits subword information, therefore making fewer out-of-vocab tokens.
Training Details
Standard data augmentations of random crop, color jitter and normalization of color are used. Images are randomly flipped with interchanging captions reasonably. SGD and linear learning rate warmup were used. Since the performance on image captioning had a positive correlation with downstram task performance, early stopping was based on the performance of visual backbone performance on downstream linear classification tasks.
4. Experiments
The six downstream tasks were selected with two mechanisms: the visual backbone is used as frozen feature, or weight initialization for fine-tuning.
4.1. Image Classification with Linear Models
Annotation Cost Efficiency
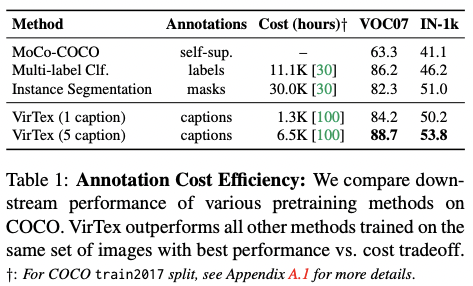
Comparison with other methods
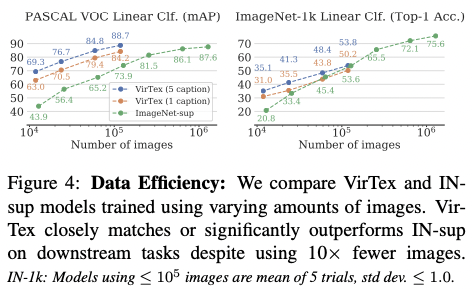
4.2. Ablations
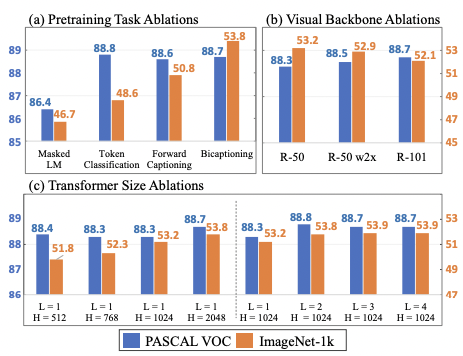
Pretraining task ablations were done to find out the effectiveness of bicaptioning. MLM seemed to lack sample efficiency, however it might benefit from longer training schedules. This was left as a future work.
Visual backbone ablations and transformer size ablations were also done as below. Bigger visual backbones resulted better downstream tasks, and it was also true in the case of the Transformer, but only before overfitting.
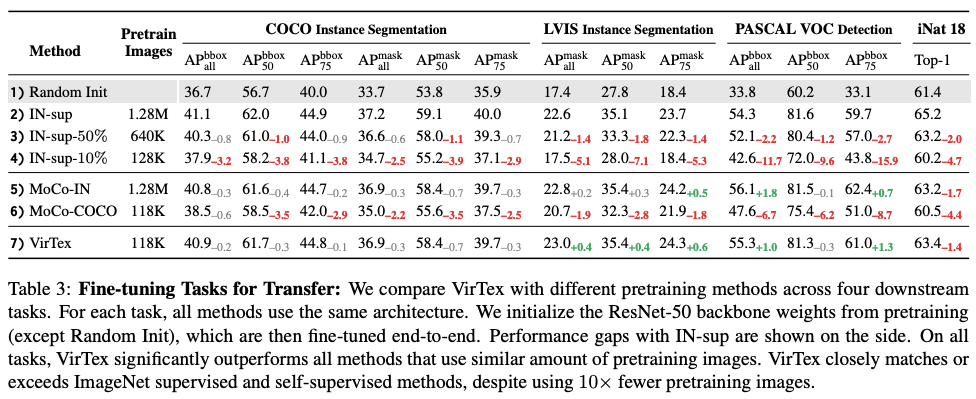
4.3. Fine-tuning Tasks for Transfer
Instance Segmentation on COCO, Instance Segmentation onLVIS, Object Detection on PASCAL VOC, Fine-grained Classification on iNaturalist 2018 are four downstream tasks used for fine-tuning of VirTex.
COCO Instance Segmentation
Mask R-CNN models with ResNet-50-FPN backbones are trained.
LVIS Instance Segmentation
Same model was used as in COCO.
PASCAL VOC Detection
Faster R-CNN models with ResNet-50-C4 backbones were used.
iNaturalist 2018 Fine-grained Classificationi
Pretrained ResNet-50 were trained end-to-end.
Results
4.4. Image Captioning

All models showed modest performance, far from SOTA which involves pretraining, but surpassed human performance on COCO. Beam search was. applied on the forward transformer decoder to decode captions which are most likely.
The 7x7 attention weights of all decoder attention modules are averaged and overlayed on 224x224 input image by bicubic upsampling, and it seemed to attends to relevant image regions for making predictions.
5. Conclusion
Using captions from web can scale up this approach, albeit more noisy than COCO.

댓글남기기