Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
https://arxiv.org/pdf/1511.06434.pdf
Abstract
DCGANs is adopted to first introduce CNNS to unsupervised learning in computer vision, and it learns a hierarchy of representations from object parts to scenes.
1. Introduction
Learning reusable feature representations form unlabeled datasets has a lot of advantages. Using GANs, and its generator and discriminator as feature extractors for supervised tasks, it can alternate maximizing maximum likelihood estimation. The researchers present:
- A set of constraints on the architectural topology of Convolutional GANs to make them stable: DCGAN
- Comparison of discriminator’s performance for classification tasks with other unsupervised techniques.
- What the filters of GANs learned to draw specific objects.
- Vector arithmetic properties of generators for easy manipulation of many semantic qualities of generated samples.
2. Related Work
2.1. Representation Learning from Unlabeled Data
A classic approach to unsupervised representation learning is to do clustering on the data, and leverage the clustering of image patches. Another method is to train auto-encoders. Deep belief networks learned well about hierarchical representations.
2.2. Generating Natural Images
There are two categories of generative image models: parametric or non-parametric.
Non-parametric models match from a database of existing images, or match patches of images, and are used in texture synthesis, super-resolution and in-painting.
Parametric models, like variational sampling approaches showed some success in generating natural images, but have problem of blurry images. GANs, laplacian pyramid extension, recurrent network approach and a deconvolution network approach showed some successful result, but they did not leveraged the generators for supervised tasks.
2.3. Visualizing the Integrals of CNNs
In the CNNs, by using deconvolution and filtering the maximal activations, approximate purpose of each convolution filter in the network can be observed. Similarly, using a gradient descent on the inputs, one can inspect the ideal image that activates certain subsets of filters.
3. Approach and Model Architecture
There was three main modification:
-
All convolutional net
Replaces all deterministic spatial pooling functions with strided convolutions. This allows the network to learn own spatial downsampling.
-
Eliminating fully connected layers on top of convolutional features
Global average pooling increased model stability, but hurt convergence speed. A middle ground of directly connecting the highest convolutional features to the input and output respectively of the generator and discriminator worked well. The first layer of the GAN can be reshaped in 4-dimensional tensor, and used as an initiator of a convolution stack. For the discriminator, the last convolution layer is flattened and fed into a single sigmoid output.
-
Batch Normalization
It stabilizes learning by normalizing the input to each unit to have zero mean and unit variance, helping gradient to flow in deeper layers. This was critical for deep generators to begin learning, since it prevents the generator from collapsing all samples to a single point. However, applying it to all layers resulted in sample oscillation and model instability, thus generator output and discriminator input layer was not applied batchnorm.
ReLU activation was used in the generator, without output layer with tanh. A bounded activation allowed the model to learn more quickly to saturate and cover color space of the training distribution. For the discriminator, leaky-ReLU worked well, for higher resolution.
To summarize:
Replace pooling layers to strided convolution in discriminator, and fractional-strided convolutions in generator.
Use batchnorm for both the generator and discriminator.
Remove fully connected hidden layers, for deeper architectures.
Use ReLU for generators, and use LeakyReLU for discriminator.
4. Details of Adversarial Training
Training used Large-scale Scene Understanding (LSUN), ImageNet-1k and Faces datasets. All models trained with mini-batch stochastic gradient descent with a mini-batch size of 128. Weights were initialized from a zero-centered Normal distribution. Adam optimizer was used to tune hyperparameters, unlike previous GANs which used momentum to accelerate training.
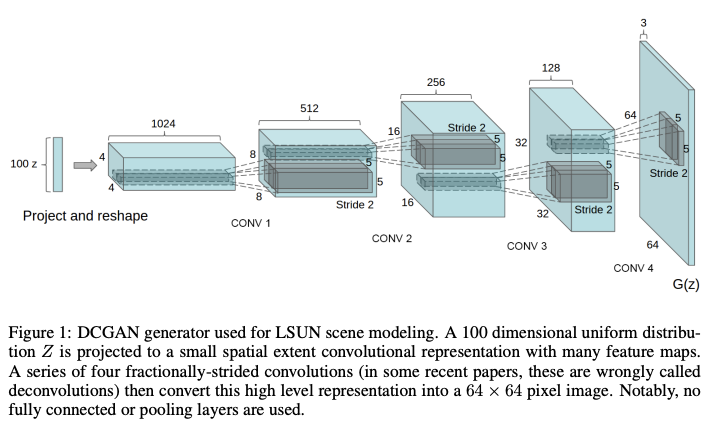
4.1. LSUN
To see if the model overfits to the dataset, compared samples from after one epoch, and after convergence. No data augmentation was applied, and there seemed to be not much memorization because there was blur in the sample after convergence.
4.1.1. Deduplication
Further decrease likelihood of the generator memorizing input examples, image de-duplication was done. A de-noising dropout regularized RELU auto-encoder was fitted, then used to detect duplicates.
4.2. Faces
Human faces and names were collected from dbpedia, who were born in modern era, and used as a dataset. With an OpenCV face detector, approximately 350,000 face boxes were collected. There was no data augmentation.
4.3. ImageNet-1k
ImageNet-1k dataset was used for unsupervised training, with no data augmentation.
5. Empirical Validation of DCGANs Capabilities
5.1. Classifying CIFAR-10 Using GANs as A Feature Extractor
To evaluate the quality of unsupervised representation learning algorithms, applying them as a feature extractor on supervised datasets, and evaluate the performance of linear models fitted on top of these features can be a useful method. For CIFAR-10, K-means can be used as a baseline for that method with high performance. Using the discriminator’s convolutional features from all layers and maxpooled to produce 4x4 spacial grid then flattened to a single vector, it outperformed the results of that of K-means, but underperformed compared to Exemplar CNN.
5.2. Classifying SVHN Digits Using GANs as A Feature Extractor
In the same way as in the CIFAR-10 case, with L2-SVM, it reached to state of art at that time. Comparing with the supervised CNN, they showed that CNN is not the key factor of the performance of DCGAN.
6. Investigation and Visualizing The Internals of The Networks
6.1. Walking In The Latent Space
To understand the landscape of the latent space, walking in the latent space method can reveal if there is any sign of memorization with sharp transitions, and if the space is hierarchically collapsed. To check if the model learned relevant and interesting representations, semantic changes to the image generation result as walking in the latent space.

6.2. Visualizing The Discriminator Features
Like supervised training of CNNs results in learning object detectors of CNN, unsupervised DCGAN can learn a hierarchy of features. Using guided backpropagation, learned features of the discriminator activate on typical objects.

6.3. Manipulating The Generator Representation
6.3.1. Forgetting To Draw Certain Objects

To see what representations the generator learns, they tried to remove windows from the generator, to explore the representation forms of the objects. With manually boxed samples, second-highest convolution layer features with logistic regression used to fit to predict if the feature activation was on a window or not. Using that criterion, all feature maps with weights higher than zero were dropped from all spatial locations, and random new samples were generated with and without the feature map removal. The samples without windows replaced with other objects.
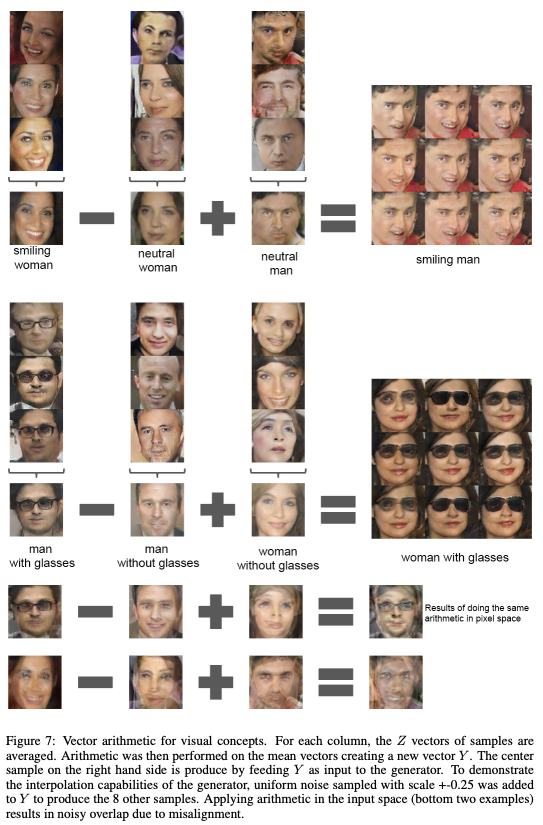
6.3.2. Vector Arithmetic on Faces Samples
With the evidence of correlation with simple arithmetic operation of latent vector and linear structure of representation space in the case of words, researched if Z representations of the generator have similar structure by doing similar operations. Working with only single sample was unstable, but averaging Z for three examples showed consistent and stable result. Previously from conditional generative models, it is shown that they can learn to convincingly model object attributes like scale, rotation, and position.
8. Conclusion and Future Work
- A more stable set of architectures for training generative adversarial networks
- Evidences for ability of GANs to learn good representations of images
- Model instability is remaining, as they sometimes collapse a subset of filters to a single oscillating mode.

댓글남기기