Training data-efficient image transformers & distillation through attention
Abstract
1. Introduction
- Neural network with no convolutional layer can achieve competitive results with the state of the art on ImageNet with no external data, and they have fewer parameters than ResNet-50 or 18.
- A new distillation precedure based on a distillation token, which role is same as class token, used to make it produce the label estimated by the teacher, is introduced. The two interact in the trasnformer through attention.
- With distillation, transformers learn more from a convnet than others.
2. Related work
-
Image Classification
Recently, ViT closed the gap with sota on ImageNet, but it needs a large training dataset.
-
The Transformer architecture
Since introduced, many improvements of convnets for image classification such as Squeeze and Excitation, Selective Kernel and Split-attention are inspired akint to self-attention.
-
Knowledge Distillation
KD refers to the training paradigm in which a student model leverages soft labels coming from a strong teacher network, which uses a teacher’s softmax function as a label. It can have a similar effect to label smoothing, or it can take into accounts of the effects of the data augmentation.
3. Vision Transformer: overview
- Multi-head Self Attention layers (MSA)
- Transformer block for images
- The class token
- Fixing the positional encoding across resolutions
4. Distillation through attention
Teacher model is a strong image classifier.
-
Soft distillation
Minimizes the KLD between the softmax of the teacher and the softmax of the student model.
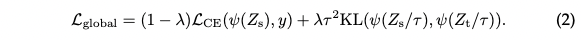
-
Hard-label distillation
Let $y_t=\argmax_c{Z_t(c)}$, then assume it as a true label. Hard label can be converted into a soft label with label smoothing.
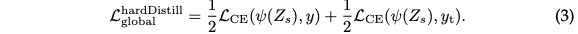
-
Distillation token
The distillation token is used as same as a class token. This helps the model to learn from the output of the teacher, while remaining complementary to the class embedding.
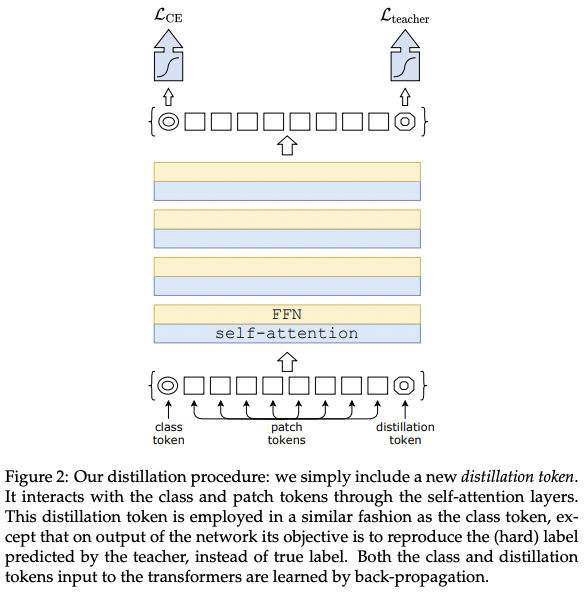
The learned class and distillation tokens converge towards different vectors, getting similar with they going through more layers, but not identical since they aiming for producing similar target.
-
Fine-tuning with distillation
Both true label and teacher prediction is used for fine-tuning stage at higher resolution.
-
Classification with our approach: joint classifiers
Both the class or the distillation embeddings produced by the transformer are associated with linear classifiers and able to infer the image label.
5. Experiments
5.1. Transformer models
The architecture is identical to that of Dosovitskiy et al., and the only difference is the training strategies and the distillation token.
5.2. Distillation
The distilled model outperformed its teacher in terms of the trade-off between accuracy and throughtput.
-
Convnets teachers
Using convnets as a teacher was better than using a transformer, since it has inductive bias and it ingerited to the transformers through distillation.
-
Comparison of distillation methods
the performance of different distillation strategies were investigated, and hard distillation outperformed all the others. The distillation token was better than using the class token, and more correlated to the convnets prediction.
-
Agreement with the teacher & inductive bias?
Checking the correlation, the distilled model was more correlated to the convnet than a transformer learned from scratch.
-
Number of epochs
Increasing the number of epochs significantly improves the performance of training with distillation, with lower saturation.
5.3. Efficiency vs accuracy: a comparative study with ocnvnets
The image classification methods are compared as a compromise between accuracy, FLOPs, number of parameters, size of the network, etc. Comparing th EfficientNet, which is sota with convnet architecture, DeiT was slightly lower but better than ViT-B.
5.4. Transfer learning: Performance on downstream tasks
To check the generalization of DeiT, transfer learning task ability should be evaluated through fine-tuning.
Comparision vs training from scratch
Pre-training was better than training from scratch.
6. Training Details & ablation
Initialization and hyper-parameters
For the initialization, recommendation of Hanin and Rolnick was adopted to initialize weights with a truncated normal distribution.
Data-augmentation
Compared to models integrate more priors such as convolutions, training Transformer with same size datasets essentially include extensive data augmentation. Auto-Augment, Rand-Augment, and random erasing were used. All of them were helpful, but dropout was not.
Regularization & Optimizers
Different optimizers were considered and cross-validated with different learning rates and weight decays. The best was the AdamW with same learning rates of ViT and smaller weight decay.
Stochastic depth was used, since it facilitates the convergence of deep transformers. Mixup, Cutmix improved the performance, and repeated augmentation also boosted performance.
Exponential Moving Average (EMA)
EMA of the network during the training was observed, but the small gains were vanished after fine-tuning.
Fine-tuning at different resolution
Data augmentation was not damped, and the positional embeddings were interpolated. Classical image scaling techniques like bilinear interpolation made a vector reduce L2-norm, and it lead to a significant performance drop since it was not adapted to the pre-trained transformers. Therefore, bicubic interpolation which approximately conserves norm of the vectors was used.
Training Time
Repeated augmentation with 3 repetitions was used, so only one third of the images is seen in a single epoch.
7. Conclusion
Using distillation, DeiT did not required a large dataset to train. Used the optimized convnet which is prone to overfitting for the teacher network. Data augmentation and regularization strategies pre-existing for convnets also helped DeiT to perform well.

댓글남기기