Learning Transferable Visual Models From Natural Language Supervision
https://arxiv.org/pdf/2103.00020.pdf
Abstract
Problem: CV systems trained to predict a fixed set of predetermined object categories → limits generality and usability since label is needed.
Solution: Learning directly from raw text about images.
Introduction
Recently, in other fields like NLP, there were evidences that learning directly from law text can be successful. However, pre-train model on crowd-labeled datasets is needed in CV.
Prior works showed that text associated with images works better than sole text(or image), but recent work of using natural language supervision for image representation learning showed a poor performance. On the other hand, more narrowly scoped or fine-tuned models showed improved performances. The researchers assumed that this was due to the scale of the database, and they constructed a new dataset of 400million pairs of image and text from the internet.
The researchers trained a CLIP(ConVIRT: contrastive language-image pre-training) from scratch, then studied the scalability of CLIP through a series of eight models. Compared to previous transformer language model or BoW prediction, CLIP showed 12x or 4x efficiency, for zero-shot classification.
Also, it could be competitive with prior task-specific supervised models.

Approach
Natural Language Supervision
All previous works used the appreciation of natural language as a training signal. The researchers summarized those as a natural language supervision. Due to the improvements in deep contextual representation learning, researchers effectively leveraged the complexity of natural language with abundant source of supervision. Since using natural language is much more scalable compare to the standard crowd-sourced labeling, it can easily scale up from various internet sources. Furthermore, it can connect representations to language, which enables a zero-shot transfer.
Creating a Sufficiently Large Dataset
Existing works mainly used: MS-COCO, Visual Genome, YFCC100M. First two have high-quality crowd-labeled datasets but have only 100,000 photos, while the last has 100M photos which only has metadata for image which is sparse and has varying quality: with only 6-15M photos with interpretable metadata with english.
Therefore, they built a new dataset of 400M pairs of image and text: WIT. The class of images was approximately balanced for 20,000pairs per query.
Selecting an Efficient Pre-Training Method
Considering the amount of work, researchers selected pre-training method based on the training efficiency as a prior metric. Previous transformer language model needs 63M parameters, which contains double ResNet-50 image encoder, three times slower than simple BoW encoder. It is because they needs to predict the exact word, which is a difficult task. Instead, they tried to train only contrastive object, which can learn better representations than predictive objects.
Clip learns a multi-modal embedding space with training text encoder and image encoder, and maximize their cosine similarity with N real image-text pairs. Symmetric cross entropy loss over similarity score is used. Due to the large size of the dataset, over-fitting was not a major concern, so details of training was simplified.
Choosing and Scaling a Model
Image encoder:
- ResNet-50 for first architecture→ widespread adoption and proven performances.
- Vision Transformer(ViT) for second architecture.
Text encoder:
- Transformer
Training
5 ResNets: ResNet-50, ResNet-101, RN50x4, RN50x16, RN50x64
3 Vision Transformers: ViT-B/32, ViT-B/16, ViT-L/14
Optimizer: Adam with decoupled weight decay regularization by cosine schedule
Initial hyper-parameter: Combination of grid search, random search, manual tuning compared with baseline of ResNet-50 trained for 1 epoch → Then adapted heuristically for larger models.
Mixed-precision was used to accelerate training and memory saving.
Gradient checkpointing, half-precision Adam statistics half-precision stochastically rounded weights for text encoder were used to save additional memory.
The largest models, RN50x64, ViT-L/14 were used for best performances and assumed as CLIP.
Experiments
Zero-Shot Transfer
Motivation
Visual N-Grams first studied zero-shot transfer to existing image classification. First, they converted the text of each dataset’s class names into n-gram representation and compute probability according to their model. Researchers focus on evaluating task learning by zero-shot transfer learning.
Using CLIP for Zero-Shot Transfer
CLIP is pre-trained to predict an image and a text snippet is paired together. First, compute the feature embedding with that feature. Then calculated cosine similarity is scaled by a temperature parameter tau, normalized by softmax to a probability distribution. Last prediction is multinomial logistic regression classifier, L2-normalized. In this approach, the image encoder becomes the CV backbone for feature representation, and the text encoder becomes a hypernetwork that generates the weights of a linear classifier based on the text specifying the visual concepts of the class. For evaluation, cache the zero-shot classifier computed by the text encoder, then use it for all subsequent predictions.
Initial Comparison to Visual N-Grams
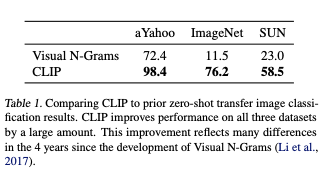
CLIP model improved accuracy on ImageNet by 76.2%, which matches the original ResNet-50 without using 1.28M crowd-labeled training examples. Also, top-5 accuracy was 96%, as near as Inception-V4.
Prompt Engineering and Ensembling
The vast majority of datasets lacks the context of the meaning of the given labels for the images. Meanwhile, the text given for an image should be a single sentence. Therefore, researchers used a prompt template of A photo of a {label}, and it increased accuracy on ImageNet by 1.3%. Likewise, using a prompt template specified to each database helped increasing performance.
Using different context prompt, multiple zero-shot classifiers can be computed. Then they used the ensemble of the embedding space instead of probability space. This way, a single averaged text embedding is the only thing should be cached, and additional performance increase of 3.5% can be achieved compared to a single default prompt case.
Analysis of Zero-Shot CLIP Performance
For the fine-grained classification tasks, CLIP outperformed the logistic regression on ResNet-50, and for the general object classification datasets, the score was relatively similar. On the other hand, for specialized or complex tasks such as satellite image classification, it underperformed.
Since CLIP’s zero-shot classifier is generated by natural language, context-less example can have a drawback, since a single image can contain multiple concepts. Therefore, 4-shot logistic regression was matched to zero-shot CLIP.
Comparing CLIP’s performance with a fully supervised linear classifiers, there was a positive correlation of 0.82.
Representation Learning
Task-learning probability can be analyzed by studying the representation learning capacities of a model, and fitting a linear classifier on a representation extracted from the model and measuring its performance on various datasets can achieve this.
All CLIP models outperformed all evaluated systems in terms of compute efficiency.
Robustness to Natural Distribution Shift
Effective robustness measures improvements in accuracy under distribution shift, and relative robustness measures improvements in out-of distribution accuracy.
“””Not completed yet”””
Comparison to Human Performance
In human test, performance increased considerably with just one example. It seemed that there was a difference with how human and CLIP trains on a few examples, and there seemed to be some algorithmic improvements that can decrease the gap between human and machine sample efficiency. The key point would be the way of the effective use of prior knowledge.
Data Overlap Analysis
Since the database was gathered from the internet source, there can be a possible problem of containing multiple duplicates and lacks generalization. It can be prevented by removing all the duplicates, but it requires knowledge about all possible data, which limiting the scope of analysis. Thus, researchers documented how much the overlap occurs and how performance changes according to the overlaps. First, they made a three dataset using duplicate detector which detects the duplicated image. Then they computed the zero-shot accuracy of a CLIP on the three splits. Since the amount of overlap was small, overall accuracy shifted around only 0.6% for the largest overlap of 12.1%. However, there is still chances that the detector was not perfect, or the data distribution was not shifted by the overlap.
Limitations
- Since the baseline performance is below the overall state of the art, there is still significant work needed to improve the task learning and transfer capabilities of CLIP. However, the required compute is 1000x more than current state, which is infeasible.
- Compared with task-specific models, CLIP underperforms for difficult or specialized tasks, or novel tasks which needs data lacks in pre-training dataset.
- Since the required validations sets needed thousands of examples, the zero-shot scenario could be not realistic.
- Additionally, since the images from the internet was not curated, the model could train some social biases.
- Many complex tasks or visual concepts are difficult to explained through a plain text, so actual useful training examples dost not optimized for few-shot performance, which is different from the human case.
Broader Impacts
- CLIP makes it possible to create new classes for categorization, without re-training.
- CLIP in zero-shot setting can be used for various widely-applicable tasks like image retrieval or search.
Bias
Since all tasks can all contribute to or amplify social biases, CLIP also needs to be analyzed.
Related Papers
Pre-training method: Learn directly from raw text
- Dai, A. M. and Le, Q. V. Semi-supervised sequence learning. In Advances in neural information processing systems, pp. 3079–3087, 2015.
- Howard, J. and Ruder, S. Universal language model fine-tuning for text classification. arXiv preprint arXiv:1801.06146, 2018.
Text-to-Text
- McCann, B., Keskar, N. S., Xiong, C., and Socher, R. The natural language decathlon: Multitask learning as question answering. arXiv preprint arXiv:1806.08730, 2018.
GPT-3
- Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. arXiv preprint arXiv:2005.14165, 2020.
Multi-Class N-Pair loss
- Sohn, K. Improved deep metric learning with multi-class n-pair loss objective. In Advances in neural information processing systems, pp. 1857–1865, 2016.

댓글남기기