Image-to-Image Translation with Conditional Adversarial Networks
Abstract
Conditional adversarial networks as a general-purpose solution to image-to-image translation.
1. Introduction
Many problems in image processing incolve image translation. GANs can generate images that reach high-level goals, but the general-purpose use of cGANS were unexplored.
2. Related work
Structured losses for image modeling
Image-to-image translation problems are often formulated as per-pixel classification or regression, treating the output space as unstructured with every output pixel is independent from all the other. Unlike this, cGANs learn a structured loss that penalizes the joint configuration of the output.
Conditional GANs
cGANs were previously used conditioned on discrite labels, text and images. Unconditioned GANs were also used for image-to-image translation, but needed other terms like L2 regressions. Therefore, these approaches needed a tailored tuning for each tasks.
U-Net based architecture was used for the generator, and PatchGAN was used for the discriminator, to penalizes structure at the scale of image patches.
3. Method
Unlike the GANs learning a mapping of $G:z\rightarrow\,y$, cGANs learn $G:{x,z}\rightarrow\,y$.
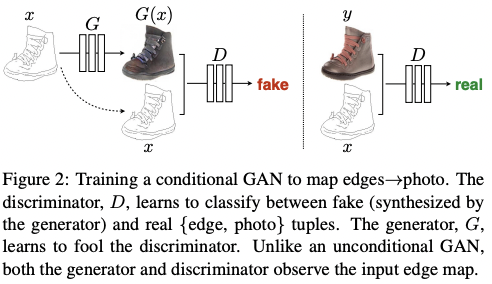
3.1. Objective
The objective of a cGAN is given as:
\[\mathcal{L}_{cGAN}(G,D)=\mathbb{E}_{x,y}[\log{D(x,y)}]+\mathbb{E}_{x,z}[\log(1-D(x,G(x,z)))]\]Also, to investigate the importance of conditioning the discriminator, compare this with:
\[\mathcal{L}_{cGAN}(G,D)=\mathbb{E}_{y}[\log{D(y)}]+\mathbb{E}_{x,z}[\log(1-D(G(x,z)))]\]According to previous approaches, mixing GAN objective with traditional losses like L2 distance is helping. To encourage less blurring, apply L1 distance to the objective:
\[\mathcal{L}_{L1}(G)=\mathbb{E}_{x,y, z}[\|y-{G(x,z)}\|_1]\] \[G^*=\arg\min_G\max_D\mathcal{L}_{cGAN}(G,D)+\lambda\mathcal{L}_{L1}(G)\]Since the generator tended to ignore the noise provieded in the input, noises are only provided in the form of dropout, applied on several layers of generator both training and test time. However, the dropout noise left only minor stochasticity in the output, leaving designing highly stochastic cGAN a future work.
3.2. Network architectures
3.2.1. Generator with skips
In defined translation problems, both the input and output are roughly alined with structure. Encoder-decoder network can be a solution to these cases. To give the generator a means to circumvent the bottleneck, skip connections are added.
3.2.2. Markovian discriminator (PatchGAN)
Since L1 term can capture the low frequencies, it is sufficient to enforce modeling high-frequencies. PatchGAN tries to classify each N x N patch in an image, and this discriminator is ren convolutionally across the image, and all responses are averaged to provide the ultimate output of D.
N can be much smaller than the full size of the image, with fewer parameters. The discriminator models the image as a Markov random field, assuming independence between pixels separated by more than a patch diameter, being a form of texture and style loss.
3.3. Optimization and inference
Gradient steps are alternated between D and G in the training. At the inference time, dropout was applied as the testing and batch normalization was applied with the statistics of the test batch, not using aggregating the ones of training. Batch normalization with the batch size of 1, instance normalization, has been demonstrated to be effective at image generation tasks.
4. Experiments
- Semantic labels ↔ photo
- Architectural labels → photo
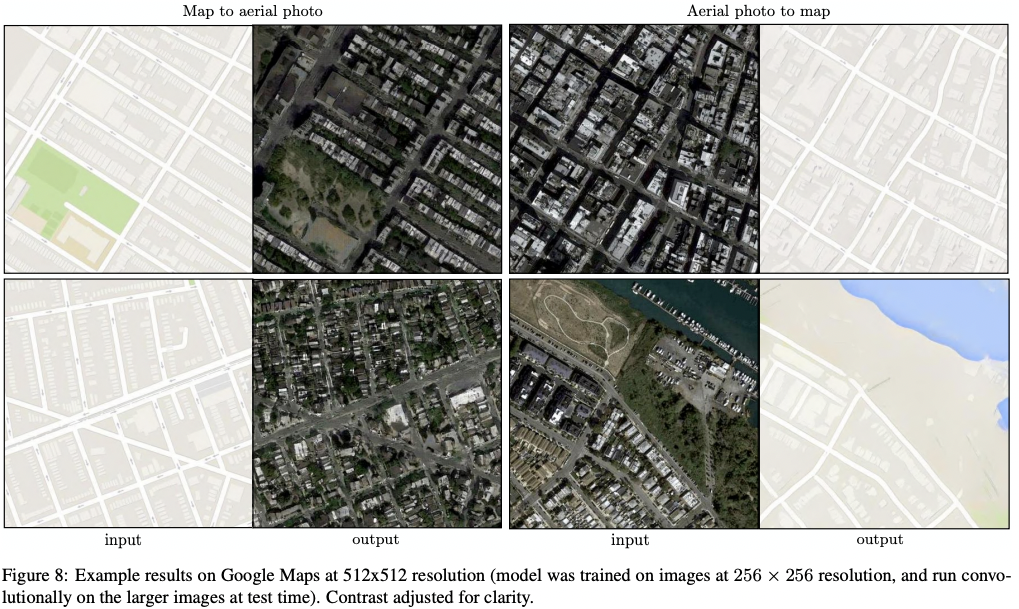
- Map ↔ aerial photo
- BW → color photos
- Edges → photo
- Sketch → photo
- Day → night
- Thermal → color photos
- Photo with missing pixels → inpainted photo
Data requirements and speed: even on small datasets, decent results could be obtained, with short training time and even shorter inference time.
4.1. Evaluation metrics
To hollistically evaluate the visual quality of synthesized images, firstly, preceptual studies were run on Amazon Mechanical Turk (AMT), since the plausibility to a human observer is often the ultimate goal. Secondly, off-the-shelf recognition system were used to find out if the images were realistic enough to recognize objects, which is a similar way to the Inception Score, or Semantic Interpretability.
AMT perceptual studies
Turkers were presented with a series of trials that pitted a real image against fake images.
FCN-score
Pre-trained semantic classifiers are used to measure outputs of the generative models. FCN-8s architecture was used, and trained on the cityscapes dataset. Then, score synthesized photos are scored by the classification accuracy against the labels.
4.2. Analysis of the objective function

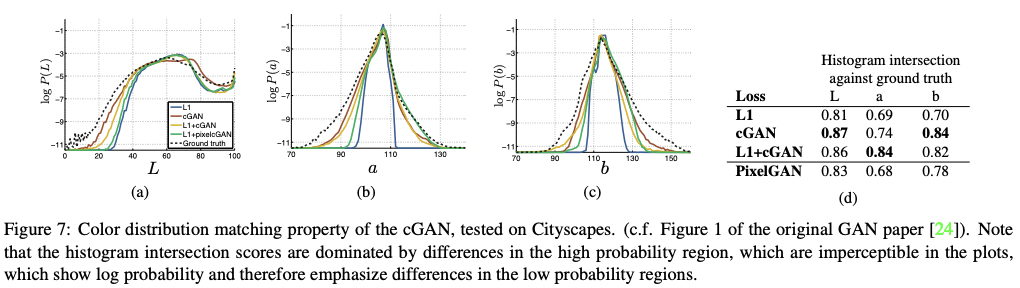
Adding both the cGAN and L1 term resulted best. Removing conditioning from the discriminator made the loss to ignore mismatch between the input and output, and only care about if the output was realistic. This resulted in poor performance, collapsing into producing nearly the exact same output regardless of input photograph. L1 + GAN was also effective at creating realistic renderings that respect the input label maps.
Colorfulness
cGANs can produce sharp images, hallucinating spatial structure which were not in the input. Using cGANs pushes the output distribution to the ground truth, helping sharp L1 distribution which leads to gray and blurry output.
4.3. Analysis of the generator architecture
In the generator, the encoder-decoder was unable to learn to generate realistic images, since it lacked informations from higher resolutions.
4.4. From PixelGANs to PatchGANs to ImageGANs

With varying patch sizes, 16 x 16 PatchGAN was sufficient to make sharp image, and achieve good FCN-scores. Scaling up does not improved the results, even getting lower FCN-scores, maybe due to more parameters made it hard to train.
Fully-convolutional translation
Like PatchGAN can be interpreted as a fixed-size patch discriminator, generator can be applied as convolutionally on larger images than used in training.
4.5. Perceptual validation


In AMT experiment, L1+cGAN was better than L1 only, but poor than Zhang et al., in colorization.
4.6. Semantic segmentation

In semantic segmentation, cGANs without L1 loss were able to solve the problem. This seemed to happen because they learned the discrete labels, without learning continuous distribution of the image. However, simply using L1 regression got better scores. Reconstruction losses like L1 might be enough for less embiguous problems like segmentations.
4.7. Community-driven research
After the initial release of this paper and pix2pix codebase, many applications made from the Twitter community, to a variety of novel image-to-image translation tasks, such as Background removal, Palette generation, Sketch → Portrait, Sketch → Pokemon, Do as I Do pose transfer, edges2cat, etc.
5. Conclusion
cGANs can be a general solution to mane image-to-image translation tasks, especially involving highly structured graphical outputs.

댓글남기기