Conditional Generative Adversarial Nets
Abstract
By feeding the data y, conditioning on both the generator and discriminator is possible, and this model could learn a multi-modal model, and provide preliminary examples of an application to image tagging.
1. Introduction
In an unconditioned generative model, there is no control on modes of the data being generated. Conditioning the model on additional information makes it possible to direct the data generation process, based on class labels or some parts for inpainting, or from different modality.
2. Related Work
2.1. Multi-modal Learning For Image Labelling
In supervised learning, scaling the model to accomodate an extremely large number of predicted output categories, and probabilistic one-to-one mapping from input to output are two big problems. The first one can be leveraged with additional information from other modalities. Even a simple linear mapping from image feature-space to word-representation-space can yield improved classification performance. For the second one, conditional probabilistic generative model can be used, by taking the conditioning variable as an input and one-to-many mapping is instantiated as a conditional predictive distribution.
3. Conditional Adversarial nets
3.1. Generative Adversarial Nets
3.2. Conditional Adversarial Nets
With both the generator and discriminator are conditioned on some extra information y of any auxillary information, GANs can be extended to a conditional model. The objective function of GAN becomes:
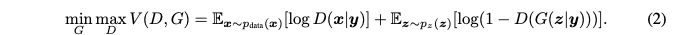
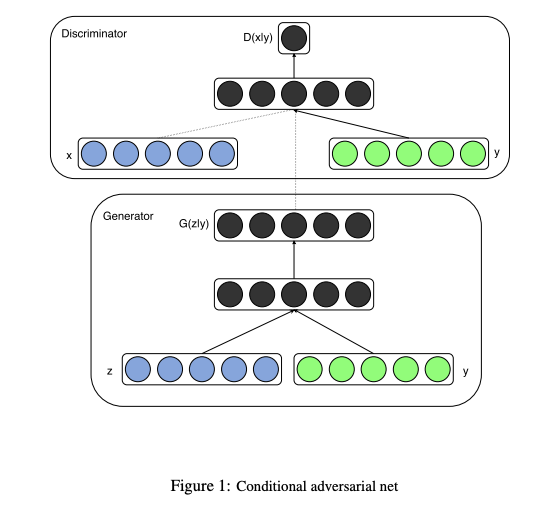
The discriminator, x and y are presented as inputs embodied by MLP.
4. Experimental Results
4.1. Unimodal
Using MNIST images conditioned on class labels encoded as one-hot vectors, the conditional adversarial net was trained to generate 784-dimensional MNIST samples. SGD and Dropout was used. The result was comparable with other networks.

4.2. Multimodal
User-generated metadata differs from canonical image labelling schems since they are more descriptive, and semantically more closer to human describing of natural language. Also, synoymy is more prevalent, making normalizing these labels more efficient.
For the image representation, the output of the last FC layer of a pre-trained CNN with ImageNet is used, and for the word representation, a skip-gram model with word vector size of 200, pre-trained with a corpus of text form concatenation of user-tags, titles and descriptions from YFCC100M is used. The CNN and the language model are fixed during the training.
Using the MIR Flickr 25,000 dataset, extracting the image and tag features using the models, 150,000 examples were used as a training set.
100 samples were generated for each image, and find 20 closest words using cosine similarity of vector representation of the words in the vocabulary to each sample for evaluation.

5. Future Work
Using multiple tags at the same time might achieve better results, and constructing a joing training scheme to learn the language model to learn a task-specific language model is remaining.

댓글남기기