An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
https://arxiv.org/pdf/2010.11929.pdf
Abstract
In vision, attention is either applied in conjunction with convolutional networks or replace certain components of convolutional networks while keeping their overall structure in place. However, Vision Transformer of pure transformer applied directly to sequences of image patches can perform very well on image classification tasks.
1. Introduction
In NLP, dominant approach is to pre-train a large text corpus and then fine-tune on a smaller task-specific dataset, and with its computational efficiency and scalability, its performance is growing with increase of the size of the model and datasets, without showing sign of saturating performance. However, in computer vision, convolutional architectures remain dominant. Inspired by the transformer success in NLP, researchers tried to apply standard Transformer directly to images. Images were split into patches and provide the sequence of linear embeddings of these patches as an input to a transformer, and the patches were treated as same as tokens.
Trained on a mid-sized datasets like ImageNet, Transformers seemed to lack some of inductive biases inherent to CNNs, such as translation equivariance and locality, so more data is needed to reach a certain amount of generality. However, trained on a larger datasets, large scale training trumps inductive bias, and performs well.
2. Related Work
Naive application of self-attention to images requires pixel by pixel computation, and this quadratic cost does not scale to realistic input size, so several approximations have been tried. For instance, there was a try with applying the self-attention only in local neighborhoods, and it could completely replace convolutions. Sparse Transformers employ scalable approximations to global self-attention. Applying attention in blocks of varying sizes is the other try to chunk down the computational cost. However, these required complex engineering to implement on hardware accelerators.
The model of Cordonnier et al.(2020) used 2x2 patches of the image then applied full self-attention. However, this small size patch restricted the model to only be applicable in small-resolution images, so the researchers used the bigger sized patch, and further demonstrated the scale of pre-training affects to the performance of the vanilla transformers.
Recent interest with combining CNNs with forms of self-attention was by augmenting feature maps for image classification or by processing the output of a CNN using self-attention. Another recent related model is image GPT(iGPT) which applies Transformers to image pixels after reducing image resolution and color space, and it was trained in an unsupervised as a generative model.
There were papers that shown RNN or ResNet based models learns better on larger scale datasets. Researchers tried to demonstrate the database scalability of Transformer.
3. Method
Trying to follow the original structure of the Transformer as possible, the advantage of the scalability of NLP Transformer architecture could be achieved. The architecture is shown as below.
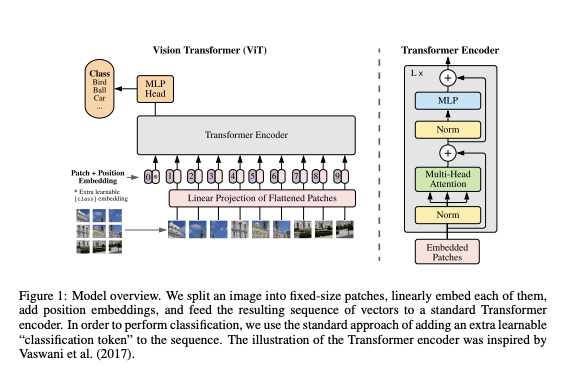
3.1. Vision Transformer ( ViT)
The Standard Transformer receives input as a 1D sequence of token embeddings, so to handle 2D images, image $\bold{x}\in\,\mathbb{R}^{\text{H}\times\text{W}\times\text{C}}$ into a sequence of flattened 2D patches $\bold{x_p}\in\mathbb{R}^{N\times(P^2\cdot\,C)}$, with patch size of (P, P) and number of patches $N=HW/P^2$. The Transformer uses constant latent vector size D through all of its layers, so the patches flattened and mapped to D dimensions with a trainable linear projection, as shown in the below.
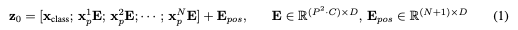
Similar to the [class] token of the BERT, learnable embedding to the sequence of embedded patches is given as $\bold{z_0^0}=\bold{x_{class}}$, and the output of the Transformer encoder $\bold{z_L^0}$ is served as the image representation y with a MLP of one hidden layer at pre-training time and single linear layer at fine-tuning time.

Positional embeddings are added to the patch embeddings to retain positional information. Standard learnable 1D position embeddings were used, since 2D-aware position embeddings showed no performance improvement.
The encoder of the Transformer is consisted of alternation layers of multiheaded self-attention and MLP blocks. Before every block, layer norm(LN) is applied and after every block, residual connections is applied.
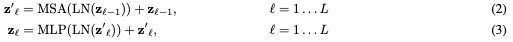
Inductive bias
Vision Transformer has much less image-specific inductive bias than CNNs, due to the lack of two-dimensional neighborhood structure and translation equivariance. Only the MLP layers are local and translationally equivariant, and two-dimensional neighborhood structure is used very sparingly. Therefore, the positional embeddings carry no information about the 2D positions of the patches, and all spatial relations between patches should be learned from scratch.
Hybrid Architecture
In hybrid model, the input sequence can be formed from feature maps of a CNN, rather than just raw image patches. The patch embedding projection E from Eq.1 is applied to patches extracted from a CNN feature map.
3.2. Fine-tuning and Higher Resulution
For the fine-tune sequence to downstream tasks, pre-train prediction head is removed and zero-initialized $D\times\,K$ feedforward layer is attached for K of a size of the downstream classes. In fine-tuning sequence, higher resolution than pre-training seemed to be beneficial since larger effective sequence length could be obtained. Since the pre-trained position embedding may no longer be meaningful, according to their original location, 2D interpolation of the pre-trained position embedding can be done.
4. Experiments
The representation learning capabilities of ResNet, ViT, and the hybrid model was evaluated by pre-train on datasets of varying size and evaluate many benchmark tasks.
4.1. Setup
Datasets
To study the model scalability, ILSVRC-2012 ImageNet dataset with 1.3M images, ImageNet-21k with 14M images, andJFT with 303M images is used. Then de-duplicated the pre-training datasets with respect to the downstream tasks.
Model Variants
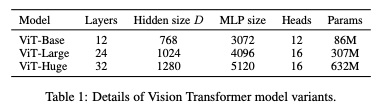
Using configurations used for BERT, base and large model was directly adopted from the BERT, and huge model is added. Since Transformer’s sequence length is inversely proportional to the square of the patch size, model with smaller patch size is more computationally expensive.
For the baseline CNNs, ResNet is used with replacing the Batch Normalization layers with Group Normalization, and using standardized convolutions, thus improving transfer.
For the hybrid model, intermediate feature maps were feed into ViT with patch size of one pixel.
Training & Fine-tuning
All models trained using Adam with $\beta_1=0.9, \beta_2=0.999$ and batch size of 4096 and high weight decay of 0.1 Linear learning rate warmup and decay was applied. For the fine-tuning, SGD with momentum, batch size of 512 is used for all models.
Metrics
Results on downstream datasets was evaluated through few-shot of fine-tuning accuracy. For the few-shot accuracies, by solving a regularized least-squares regression problem of the mapping of the frozen representation could calculate the accuracy.
4.2. Comparison to State of the Art
ViT is compared with the BiT, supervised transfer learning with large ResNets, and with Noisy Student, which is a large EfficientNet trained with semi-supervised learning on ImageNet and JFT-300M. The smaller ViT-L/16 model pre-trained on JFT-300M outperforms BiT-L on all tasks, and the larger model ViT-H/14 further improved the performances, with substantially less compute to pre-train than prior state of art.
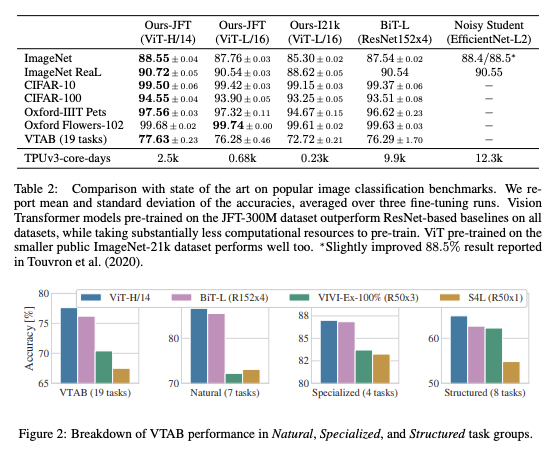
However, the pre-training efficiency seemed to be affected by both of the architecture choice, and other parameters like training schedule, optimizer, and weight decay. Studying about that feature, ViT-L/16 model pre-trained on ImageNet-21k dataset performs well with taking fewer resources to pre-train.
4.3. Pre-training Data Requirements
For fewer inductive biases for vision(compared to CNNs), researchers test the importance of size of the dataset used to train the model in two ways. First, with increasing size of different datasets, tested ViT model and evaluated the performance. Second, trained models on subsets of 9M, 30M, 90M as well as the full JFT-300M dataset. With small dataset, large models underperformed compared to small model, but with bigger dataset, the bigger model outperformed. In conclusion, convolutional inductive bias was useful for smaller datasets, but for larger ones, learning the relevant patterns directly from data is more beneficial.
4.4. Scaling Study
Studying scalability of different models by evaluating transfer performance, Vision transformers seemed to dominate ResNets on the performance/compute trade-off, and hybrids slightly outperform ViT at small computational budgets which disappears in larger models. Additionally, Vision Transformers seemed not to saturated within the tested range.
4.5. Inspecting Vision Transformer

To understand the process of processing image of the ViT, its internal representations were analyzed. The first layer of the ViT linearly projects the flattened patches into a low-dimensional space, and the principal components of the learned embedding filters resemble plausible basis functions for a low-dimensional representation of the fine structure within each patch.
From the Fig 7, the model seems to learn about 2D image topology from the positional encoding of the image. For the bigger images, a sinusoidal structure appears for bigger grids.
By computing the attention distance based on the average distance in image space, some heads seemed to attend to most of the image already in the lowest layers which means the ability of integrating global information, while the others were shown consistently small attention distances in the low layers. Deepening the network layer, attention distance increased. Globally, the model attends to image regions that are semantically relevant for classification.
4.6. Self-supervision
Like mimicking the masked language modeling task used in BERT, researchers performed a preliminary exploration on masked patch prediction for self-supervision, and it showed improvement compared to training from scratch.
5. Conclusion
From the direct application of Transformers to image recognition, scalable strategy for pre-training on large datasets could show the way to exceed the previous state-of-art. However, applying ViT to other CV tasks like detection and segmentations are remain as future tasks. Also, self-supervised pre-training methods should be explored, since there is still gap between self-supervised and supervised large-scale pre-training.


댓글남기기