A ConvNet for the 2020s
Abstract
There were some efforts to reintroduce several ConvNet priors to Transformers, hierarchical Transformers such as Swim Transformers, but the effectiveness of such hybrid approaches is still relying on the intrinsic superiority of Transformers, rather than the inherent inductive biases of convolutions.
1. Introduction
A vanilla ViT model without the ConvNet inductive biases faces many challenges in being adopted as a generic vision backbone, since it needs a global attention design, which complexity is quadratic with the input size, becoming intractable to higher resolution inputs. To avoid this, hierarchical Transformers adopted a hybrid design, reusing the sliding strategy of attention within local windows. Swim Transformer, in this way, could demonstrate the possibility for Transformers as a generic vision backbone.
While implementing convolution to Transformers is hard though its needs, ConvNets already satisfies all desired features. To investigate the ConvNet’s limits, compared it with Transformers, and modernized its design with design decisions in Transformers.
2. Modernizing a ConvNet: a Roadmap
Following different levels of designs from a Swim Transformer while maintaining the network’s simplicity as a standard ConvNet, first trained the network with similar training techniques used to train vision Transformers, and it was used as a baseline which obtained improved compared to original ResNet-50. Series of design decisions adopted can be summarized as:
- macro design
- ResNeXt
- inverted bottleneck
- large kernel size
- various layer-wise micro designs
2.1. Training Techniques
Training sequence also affects the model performance. Using training recipe similar from DeiT and Swim Transformer, such as AdamW optimizer, Mixup, Cutmix, RandAugment, Random Erasing, and regularization schemes like stochastic Depth, Label Smoothing, the performance increased with simple ResNet.
2.2. Macro Design
Swim Transformers, which following ConvNets to use a multi-stage design, has two important design considerations:
-
Changing stage compute ratio
Swim Transformers modified the computation distribution of ResNet to 1:1:3:1. Following the design, number of the blocks in each stage modified to (3, 3, 9, s3). From investigation of the distribution of computation, there seemed to be more optimal design than others.
-
Changing stem to Patchify
In Swim Transformers, a small patch size of 4 is used to accomodate the architecture’s multi-stage design. Resnet-style stem cell is modified in this way, with 4x4 and stride 4 convolutioin layer.
2.3. ResNeXt-ify
ResNeXt has a better FLOPs/accuracy trade-off than a vanilla ResNet. Using grouped convolution, in a bottleneck block, the network width is expanded with small capacity loss. Depthwise convolution, a special case of grouped convolution which equals the number of groups and channels, and already popular in MobileNet and Xception, is used in this case. It is similar to the weighted sum operation in self-attention, mixing information in the spatial dimension.
2.4. Inverted Bottleneck
Using the inverted bottleneck design, total FLOPs reduces due to reduction in the downsampling residual block shortcut 1x1 conv layer.
2.5. Large Kernel Sizes
Revisiting the use of large kernel-sized convolutions for ConvNets.
-
Moving up depthwise conv layer
With the evidence of MSA block prior to MLP layers, which indicates moving the depthwise conv layer up, inverted bottleneck block has that layer on the top of it. More complex and inefficient modules like MSA or large-kernel conv having fewer channel leads to reduction of FLOPs.
-
Increasing the kernel size
Larger kernel size seemed to reach a saturation point at 7x7, with roughly same FLOPs.
2.6. Macro Design
These are investigated at the layer level, of activation functions and normalization layers.
-
Replacing ReLU with GELU
GELU can be thought as a smoothed version of ReLU, and adopted in many advanced transformers like BERT, GPT-2 and ViTs. However, the accuray stays unchanged.
-
Fewer activation functions
There is only one activation present in the Transformer block, which is on the MLP block. To see the affect, all GELU layers from residual block except for on between 1x1 layers are removed, and it improved accuracy.
-
Fewer normalization layers
There is usually fewer normalization layers, so two BatchNorm layers are removed. Adding additional block at the beginning did not improve the performance.
-
Substituting BN with LN
BatchNorm is essential in ConvNets since it improves the convergence and reduces overfitting, but it has intricacies which detrimentally effects on the model’s performance. Simpler Layer Normalization has been used in Transformer.
-
Separate downsampling layers
Spatial downsampling is achieved in ResNet by the residual block, and in Transformers by separate downsampling layer added between stages. 2x2 conv with stride 2 is used for spatial downsampling.
3. Empirical Evaluations on ImageNet
ConvNeXt variants were made to have similar complexities to Swim-T/S/B/L.
3.1. Settings
-
Training on ImageNet-1K
Mixup, Cutmix, RandAugment, Random Erasing were used for data augmentations, and the networks were regularized with Stochastic Depth and Label Smoothing. Layer Scale is applied. Exponential Moving Average were used as it alleviates larger models’ overfitting.
-
Pre-training on ImageNet-22K
EMA were not used in this setting.
-
Fine-tuning on ImageNet-1K
AdamW is used with cosine learning rate schedule. Since there is no need to adjust the input patch size or interpolate position biases, fine-tuning is easier than in the Transformers.
3.2. Results
-
ImageNet-1K
ConvNeXt outperformed Swim-ViT with both the accuracy and FLOPs/throughput ratio.
-
ImageNet-22K
Since vision Transformers have fewer inductive biases, they perform better when pre-trained on a larger scale. In that case, ConvNeXts still perform on par or better than similar size ViTs.
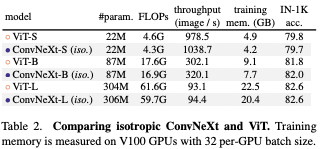
3.3. Isotropic ConvNeXt vs. ViT
To see if this ConvNeXt block can be generalized like ViT, downsampling layers are removed and feature resolutions are kept same, and the result was competitive when used in non-hierchical models.
4. Empirical Evaluation on Downstream Tasks
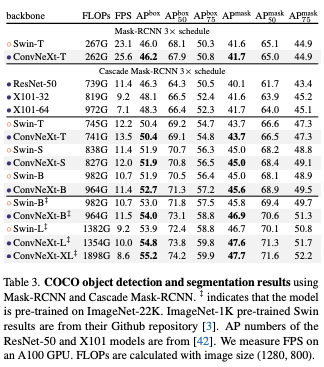
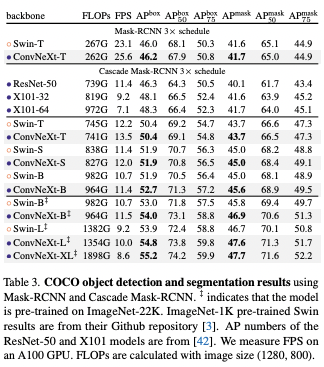
Object detection and segmentation on COCO
Training Mask R-CNN and Cascade Mask R-CNN with ConvNeXt backbone on the COCO dataset, the result was better than Swim Transformer, even with the scaled up bigger models pre-trained on ImageNet-22K.
Semantic segmantation on ADE20K
Evaluating ConvNeXt backbones on the ADE20K semantic segmentation task with UperNet, competitive performance was achieved.
Remarks on model efficiency
Although the depthwise convolutions are known to be slower and memory consumerable than dense convolutions, the inference throughputs of ConvNeXts were better than Swim Transformers and required less memory.
5. Related Work
-
Hybird models
In post-ViTs, to combine convolutions and self-attentions, focus was on augmenting a ConvNet with self-attention/non-local modules to capture long-range dependencies. Original ViT studied a hybrid configuration.
-
Recent convolution-based approaches
Han et al. showed that local Transformer attention is equivalent to inhomogeneous dynamix depthwise convolution. MSA block in Swim can be replaced with a dynamic or regular depthwise convolution in that fashion. ConvMixer uses small-scale depthwise convolution as a mixing strategy. Fast Fourier Transform can ge used for token mixing, and it is also a form of convolution, with a global kernel size and circular padding.
6. Conclusions
ConvNeXt with pure convolution can achieve similar level of scalability and better performance than ViT while retaining simplicity and efficiency of standard ConvNets.

댓글남기기